Definition (asymptotic notation)
N: sufficient large
Big-Oh O( f(N) ) T(N) = O( f(N) ) if there are a c>0 and n0 such that T(N)≤c f(N) when N≤n0
describe the growth rate (less than or equal to f(N)upper bond(worse case)
always take the smallest one (as tight as possible)
little-Oh
less than
Ω
greater than or equal (lower bound)
Θ
equals
Induction Analysis
T(N)=2T(2N)+cNT(1)=O(1)
T(2N)=2T(22N)+2cN
…
2kN=1 且 k=log2N
T(N)=NT(1)+kcN = O(N+NlogN) = O(NlogN)
Abstract Data Type
Data type = Objects + Operations
List
Objects : ( item0,item1,item2.... ) Operations : - length? - print - make an empty list - insert - delete - find next - find previous
Array
1
arry[i] = item_i
cons - max size should be estimated - Insertion and deletion O(N) and involve lots of data movement
pros - find k-th item O(1)
Linked List
cons - requires more system function calls
pros - conserve memory
List createList(List L) { L = (List)malloc(sizeof(Node)); L->next = NULL; return L; }
boolisLast(List L, Position P) { return p->next == NULL }
List insert(List L, Position P, int x) { Position tmpCell = (Position)malloc(sizeof(Node)); tmpCell->val = x; tmpCell->next = P->next; P->next = tmpCell; return L; }
ptrToNode findPre(List L, int x) { ptrToNode p = L; for(;p->net != NULL && p->next->val != x; p = p->next) { } return p }
List Delete(List L, int x) { Position pre = findPre(L, x); Position tmpCell = (Position)malloc(sizeof(Node)); tmpCell = pre->next; pre->next = tmpCell->next; free(tmpCell); }
1
std::list<int> L;
Stack
LIFO
ADT error: pop from an empty stack
Implementation error: push to a full stack
Implementation
definition
1 2 3 4 5 6 7
typedefstructstackRecord* Stack;
structstackRecord{ int capacity; int top; int* array; };
intpop(Stack S) { if(0 == S->top) { exit(EXIT_FAILURE); } else { return S->array[S->top--]; } }//pop and top
Utilities
1.Infix to Postfix Conversion
When encountering an operator, push it onto the stack. For operators with higher priority, pop out all operators with lower priority before pushing them onto the stack. When encountering a right parenthesis, pop out all operators until a left parenthesis is encountered.
2.Postfix Evaluation
When encountering a number, push it onto the stack. When encountering an operator, pop out two numbers, perform the calculation, and push the result back onto the stack.
e.g.
Push 5 characters ooops onto a stack. In how many different ways that we can pop these characters and still obtain ooops?
5
Queue
FIFO
Implementation (Circular)
definition
1 2 3 4 5 6 7 8 9
typedefstructqueueRecord* Queue;
structqueueRecord { int capacity; int size;//not necessary int front; int rear; int* array; }
average searching time: $$\frac{\sum \text{search counts}}{\text{number of elements}}$$
Quadratic probing
f(i)=i2
Theorem : if table size is prime, a new element can always be inserted if the table is half empty (λ<21)
1 2 3 4 5 6
CollisionNum = 0; CurPositon = hash(Key, table); while(!CurPosition empty && CurPosition != key) {//delete === set the flag to empty CurPosition += 2 * ++CollisionNum - 1//induction of (hash(key) + f(i)) if(CurPosition >= TableSize) CurPosition -= TableSize; //mod tablesize(speed up by using '-' as opposed to '%') }
2 Separate chaining
3 Double Hashing
f(i)=i∗hash2(x)−−e.g.R−(xmodR) noted that R is a prime number smaller than table size
Overflow
Rehashing
if λ>21 there might happen insertion fail
the new table size is a prime which is at least two times bigger than the previous one
when rehash?
1 as soon as half full
2 when insertion fail
3 when the table reaches a certain load factor
e.g.
The average search time of searching a hash table with N elements is
can’t be determined O(1) to O(N)
Tree
Properties
depth : the length from root to the specific node depth(root) = 0
height : the length of the longest path from the node to a leafheight(leaf) = 0
Traversal
Tree traversal: liner time complexity
Graph traversal: number of edges + vertices
Preorder Traversal ⇒ Postfix Expression
print root node first
deep into the hierarchy. On meeting a node, print it
if can not deep in, go back and find another way
1 2 3 4 5 6 7 8
voidpreOrder(Tree T) { if(T) { //tree != NULL (stop and return when reaching the child of leaf) visit(T) //on meeting a tree node, print it for(each child C of T) { preorder(C); } } }
Postorder Traversal ⇒ Prefix Expression
deep in as far as possible
meet NULL
return and print
1 2 3 4 5 6 7 8
voidpostOrder(Tree T) { if(T) { for(each chlid C in T) { postOrder(C); } visit(T); //first reach here when every child of T is NULL(T is a leaf) } }
Levelorder Traversal (with queue ADT)
visit level by level
1 2 3 4 5 6 7 8 9
levelOrder(Tree T) { enQueue(T); while(queue is not empty) { visit(T = deQueue()); for(each child C in T) { enQueue(C); } } }
Heap percolateUp(Heap H, int Idx) { int i = Idx; int x = H->array[Idx]; for(; H->array[i/2] < x; i /= 2) { H->array[i] = H->array[i/2]; } H->array[i] = x; return H; }
Heap percolateDown(Heap H, int Idx) { int x = H->array[Idx]; int i = Idx; int child; for(; (i * 2) <= H->size; i = child) { child = i * 2; if((child < H->size) && (H->array[child] < H->array[child + 1])) { child++; } if(H->array[child] > x) { H->array[i] = H->array[child]; } else { break; } } H->array[i] = x;
return H; }
build Heap (linear time complexity)
1 2 3 4 5 6 7 8 9
int seq[]; memcpy(H->array, seq, sizeof(seq)); H->array[0] = INT_MAX; int size = sizeof(seq)/sizeof(int); //build heap from bottom to the top //procolate down (start from first non-lraf node) for(int n = (size - 1) / 2; n >= 1; n--) { percolateDown(H, n); }
Element type (int): This is the data type of the elements in the priority queue. In this example, we are using the int type.
Container type (std::vector<int>): This is the type of container used to store the elements of the priority queue. std::vector is a dynamic array in the C++ standard library that provides random access and dynamic resizing capabilities. In this example, we are using std::vector<int> as the container, which means the elements of the priority queue will be stored in a dynamically sized array of integers.
Comparator (std::greater<int>()): This is the comparator used to determine the priority of elements. std::greater<int>() is a template function that defines the comparison rule for two int type elements, i.e., a > b. When creating a min-heap, we use std::greater<int>() as the comparator, so that the top element of the heap will be the smallest element in the heap.
Disjoint Set
Elements of the sets: 1, 2, 3, 4, … N
Sets: S1,S2,S3...SnSi∩Sj=∅
Let T be a tree created by union-by-size with N nodes, then the height of T can be
at most log2(N)+1
There exists a binary tree with 2016 nodes in total, and with 16 nodes having only one child.
F 0⋅x0+1⋅x1+2⋅x2=edge
Graph
Topological Sort
AOV network
activities on the vertex E(G) represent the precedence relations i is a predecessor of j ( j is the successor of i ), existing a path i→j
irreflexive ( i→i is illegal )
//get indegree of all the vertex vector<int> indegree;
voidTopsort(Graph G){ vector<int> que; int Counter = 0; auto tar = ranges::find(indegree.begin(), indegree.end(), 0); que.push_back(tar - indegree.begin()); while(!que.empty()) { int V = que.back(); counter++; que.pop_back(); for(each W adjacent to V) { if(0 == --indegree[W]) { que.push_back(W); } } } if(counter != number of vertex) { //exist a circle }
}
time complexity O(∣V∣2+∣E∣)=O(∣V∣2)
Unweighted Graph (Shortest Path) -> BFS
time complexity : O(∣E∣+∣V∣)
1 2 3 4 5 6 7 8 9 10 11 12
vector<int> que; que.push_back(src) //enquue src vertex while(!que.empty()) { int V = que.back(); que.pop_back(); for(each W adjacent to V) { if(!visited[W]) { visited[W] = true; dist[W] = dist[V] + 1; } } }
Weighted Graph (Shortest Path) -> Dijkstra Algo
O((∣V∣+∣E∣)∣V∣)
with min heap : O((∣E∣+∣V∣)log(∣V∣))
Dijkstra(Graph G, int src) { vesited[src] = true; dist[src] = 0; int dijIdx = 0; dijSeq[dijIdx] = src; for(dijIdx = 1; dijIdx < V_NUM; dijIdx++) { int V; int minDist = INT_MAX; int minV; for(V = 0; V < V_NUM; V++) { if(!visited[V] && dist[V] < minDist) { minV = V; } } visited[V] = true; for(each W adjacent to V) { dist[W] = min(dist[W], dist[V] + edge[V][W]); } } }
Weighted Graph with negative weight (Shortest Path)
O(∣V∣×∣E∣)
1 2 3 4 5 6 7 8 9 10 11
dist[src] = 0 enqueue(src); while(!que.empty()) { int V = dequeue(); for(each W adjacent to V) { update min dist of W; if(ranges::find(que.begin(),que.end(), W) == que.end()){ //not found enqueue(W) } } }
Minimal Spanning Tree
Prim’s Algo
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
int src; dist[src] = 0; visited[src] = true
for(each W adjacent to src) { update dist[W]; } for(int i = 1; i < V_NUM; i++) { find an unvisited vertex with minimal dist = V for(each W adjacent to V) { update dist[W]; } MST[cnt++] = W; }
Kruskal’s Algo
1 2 3 4 5 6 7 8
Kruskal(G): 1. Sort all the edges of graph G in non-decreasing order of their weight. 2. Initialize an empty set MST to store the minimum spanning tree. 3.for each edge e in the sorted edge list: 4.if adding edge e to MST does not form a cycle: //using disjoint Set 5. Add edge e to the MST. 6. Return MST.
Uniqueness of MST
perform Kruskal’s algo
- when encountering an edge where the starting point and ending point are already in the same connected component, the code checks if this edge has been marked as known. If the edge is marked as known, it indicates that this edge is not a unique minimum spanning tree edge
function FordFulkerson(Graph, source, sink): for each edge in Graph: (u, v) = edge.start, edge.end edge.flow = 0
maxFlow = 0 while (there is a path from source to sink in the residual network): // Find the path with available capacity in the residual network pathFlow = findPath(Graph, source, sink)
// Update the flow along the path for each edge in the path: edge.flow += pathFlow reverseEdge(edge).flow -= pathFlow
// Add path flow to overall flow maxFlow += pathFlow
return maxFlow
Find strongly connected components
DFS -> get a sequence
reverse Graph
DFS : source node according to the sequence (unvisited->add to a connected component)
Path: only one vertex indegree = outdegree + 1, another outdegree = indegree + 1
Sorting
Any ALGO that sort by exchanging adjacent elements requires Ω(N2) eliminate one inversion once
Any ALGO sorting by comparison only worst case O(NlogN)
Common stable sorting algorithms include:
Bubble Sort
Insertion Sort
Merge Sort
Radix Sort
Common unstable sorting algorithms include:
Selection Sort
Quick Sort
Shell Sort
Heap Sort
Bubble Sort
1 2 3 4 5 6 7 8 9 10 11
voidbubbleSort(int arr[], int n) { for (int i = 0; i < n-1; i++) { for (int j = 0; j < n-i-1; j++) { if (arr[j] > arr[j+1]) { int temp = arr[j]; arr[j] = arr[j+1]; arr[j+1] = temp; } } } }
Insertion Sort
1 2 3 4 5 6 7 8 9 10 11 12
voidinsertionSort(int arr[], int n) { int i, key, j; for (i = 1; i < n; i++) { key = arr[i]; j = i - 1; while (j >= 0 && arr[j] > key) { arr[j + 1] = arr[j]; j = j - 1; } arr[j + 1] = key; } }
Merge Sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
voidmerge(int arr[], int l, int m, int r) { // Merge two subarrays of arr[] // First subarray is arr[l..m] // Second subarray is arr[m+1..r] // Merge the subarrays }
voidmergeSort(int arr[], int l, int r) { if (l < r) { int m = l + (r - l) / 2; mergeSort(arr, l, m); mergeSort(arr, m + 1, r); merge(arr, l, m, r); } }
Selection Sort
1 2 3 4 5 6 7 8 9 10 11 12 13 14
voidselectionSort(int arr[], int n) { int i, j, min_idx; for (i = 0; i < n-1; i++) { min_idx = i; for (j = i+1; j < n; j++) { if (arr[j] < arr[min_idx]) { min_idx = j; } } int temp = arr[min_idx]; arr[min_idx] = arr[i]; arr[i] = temp; } }
Shell Sort (with Shell Increment)
1 2 3 4 5 6 7 8 9 10 11 12
voidshellSort(int arr[], int n) { for (int gap = n/2; gap > 0; gap /= 2) { for (int i = gap; i < n; i++) { int temp = arr[i]; int j; for (j = i; j >= gap && arr[j - gap] > temp; j -= gap) { arr[j] = arr[j - gap]; } arr[j] = temp; } } }
Shell Increment
best case O(kN)=O(N)
worst case O(N2)
Hibbard Increment
worst case O(N23)
average case O(N45)
Heap Sort
build Heap O(N) or O(logN)
delete min for N times (O(N⋅logN)
the space requirement is doubled (malloc an extra buffer to store the sorted array)
voidswap(int *a, int *b) { int temp = *a; *a = *b; *b = temp; }
intmediumThree(int A[], int left, int right) { int center = (left + right) / 2; if (A[left] > A[center]) swap(&A[left], &A[center]); if (A[left] > A[right]) swap(&A[left], &A[right]); if (A[center] > A[right]) swap(&A[center], &A[right]);
voidQsort(int A[], int left, int right, int cutoff) { if (right - left >= cutoff) { int pivot = mediumThree(A, left, right); int i = left; int j = right - 1;
for (;;) { while (A[++i] < pivot) {} while (A[--j] > pivot) {}
if (i < j) { swap(&A[i], &A[j]); } else { break; } }
swap(&A[i], &A[right - 1]);
Qsort(A, left, i - 1, cutoff); Qsort(A, i + 1, right, cutoff); } }
T(N)=T(i)+T(N−i−1)+cN
worst case : T(N)=T(N−1)+cN=O(N2) every pivot is the first element
best case : T(N)=2T(2N)+cN=O(NlogN)
average case : O(NlogN)
1 2 3 4 5 6
qsort(void* base, size_t num, size_t size, int(*cmp)(constvoid* a, constvoid* b))
intcmp(constvoid* a, constvoid* b) { return *((int*)a) - *((int*)b); //return *((int*)b) - *((int*)a); }
Bucket Sort
The key is to know the range in advance and then allocate different buckets reasonably.
Radix Sort
First compare the numbers with the smallest impact on the data (ones place) Put them into buckets 0-9 respectively Then compare the tens place and put them into buckets 0-9 in order Finally, compare the hundreds place
Another example is sorting playing cards by suit first and then by number.
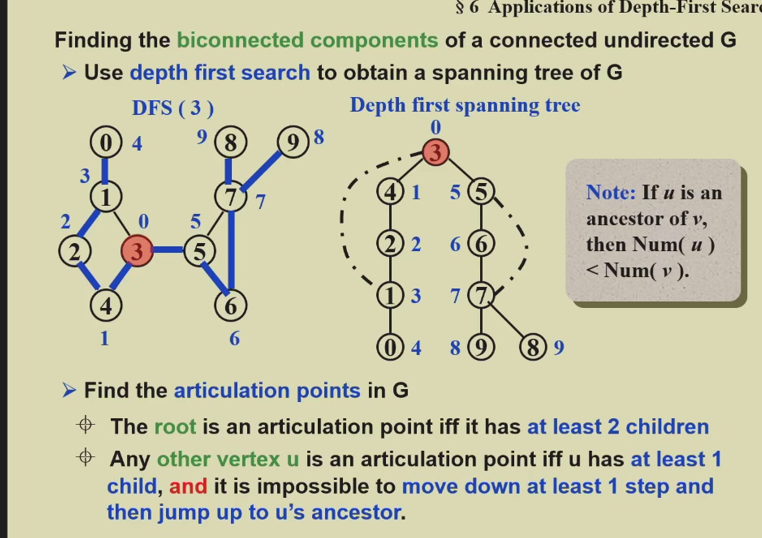
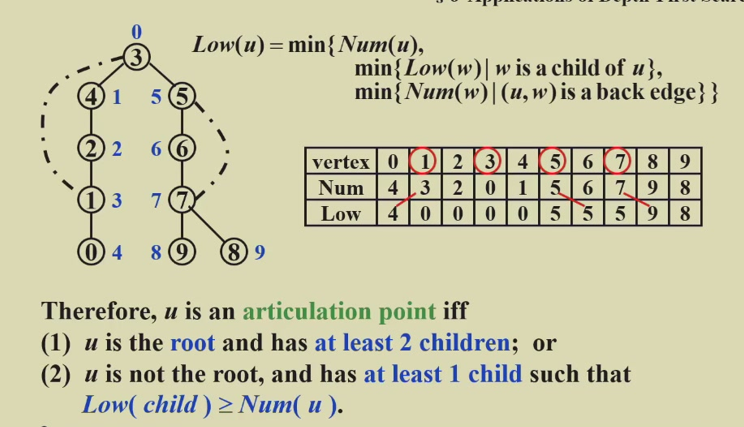
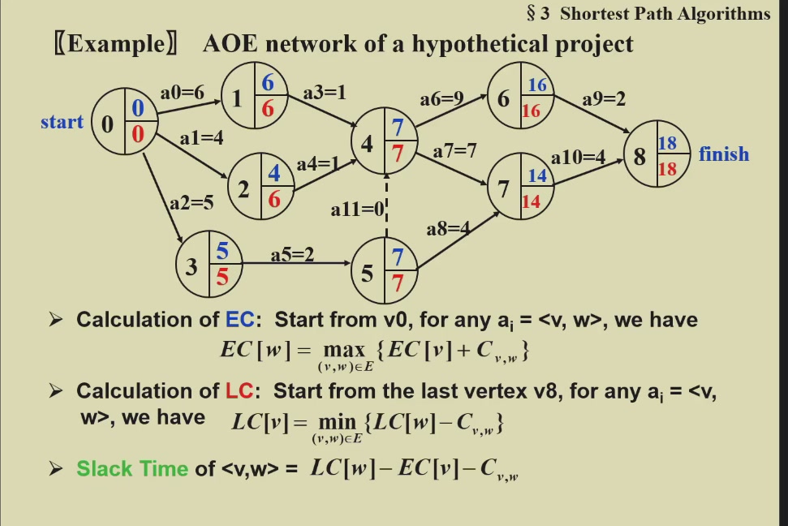 Earliest Event
Latest Event
Earliest Activity
Latest Activity
Earliest Event
Latest Event
Earliest Activity
Latest Activity



![[CTF实战]QQ盗号网站SQL注入攻击](https://s2.loli.net/2024/07/15/kdInMjAyZSuUBb7.png)
![[课程笔记]2024春夏 ZJU 数据结构基础](https://s2.loli.net/2024/07/15/tZBwHEjfqLKs45x.png)
![[misc]网站搭建中使用的python脚本和HTML前端代码](https://s2.loli.net/2024/07/15/eM2UuLr5t37XmF9.png)
![[CS学习]计算机网络](https://s2.loli.net/2024/07/15/3gzkTo129CQZXKP.png)
![[CTF技术]SQL注入攻击](https://s2.loli.net/2024/07/14/AJYsj9Mu2VKmHnz.png)