[CS学习]计算机网络
学习计算机网络的一点点记录。
不能称得上系统全面,仅仅是一些实践中碰到的豆知识
曾经在老爸的力荐下看了《图解 TCP/IP》这本书。虽然这本书的讲解和例子确实通俗易懂,但是面对网络这种看不见摸不着的神秘力量 ,看了大半以后还是感觉一知半解。直到经过 CTF 短学期的历练以后,通过实际抓包网络流量并且分析,了解前后端的语言、逻辑,才算是对她有一些感觉。对我来说,在真正动手做以后才能更全面立体地了解一个新的知识或是领域。The best way to learn something is to implement it by yourself!
概述
DNS: 以www.baidu.com为例
- IP 地址:就像一栋房子的门牌号,它是唯一的,可以用来找到具体的位置。在网络中,IP 地址用于唯一标识一台设备,使得其他设备可以找到并与其通信。
- DNS:类似于电话簿,它将域名(比如 www.example.com)映射到IP地址(比如 192.0.2.1)。就像你在电话簿中查找某个人的名字以找到他们的电话号码一样,DNS 用于将人类易读的域名转换为机器易读的 IP 地址。
人们如果要记住各个网站的 IP 地址再去访问就太麻烦了,于是直接输入一个域名(www.baidu.com)让DNS服务器去找它对应的IP地址再去访问就好了
指令
1 | nslookup |
可以查询某个域名的 IP 地址 也可以通过 IP 地址反向查询域名
例如
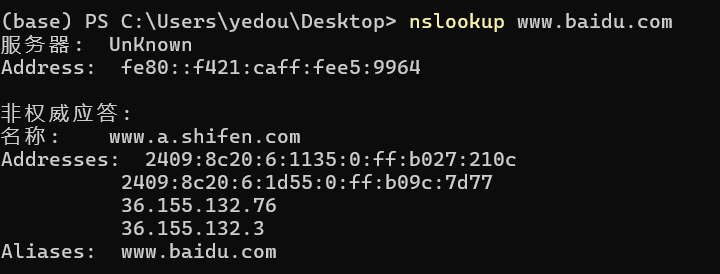 www.baidu.com
是www.a.shifen.com的别名(*Aliases*)
其 IPv4 与 IPv6 地址为……
www.baidu.com
是www.a.shifen.com的别名(*Aliases*)
其 IPv4 与 IPv6 地址为……
1 | 2409:8c20:6:1135:0:ff:b027:210c |
非权威应答:来自缓存解析器的响应。DNS 解析器会缓存之前查询过的 DNS 记录,以提高后续查询的速度和减少网络负载。这种缓存数据可能不是最新的,但通常在有效期内是可靠的
可能 IP 地址已经更新了,但是 DNS 缓存中依然是旧的,有不正确的可能。
如何获得最权威的应答(准确无误的 IP 地址)
从最根部的服务器开始询问,一层一层递归询问
Step1
1 | nslookup -qt=NS . |
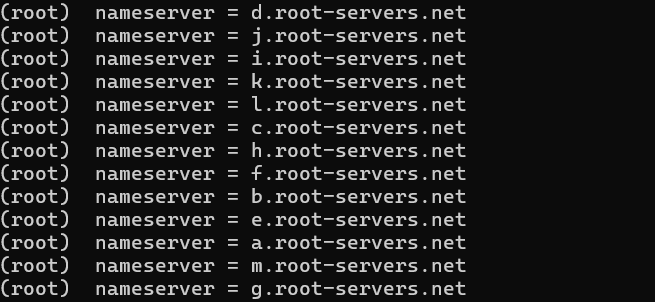 查找 `.`域名的 DNS 服务器
根 DNS 服务器是 DNS 层次结构的顶层,它们知道所有顶级域(如 `.com`, `.org`, `.net`)的权威 DNS 服务器
查找 `.`域名的 DNS 服务器
根 DNS 服务器是 DNS 层次结构的顶层,它们知道所有顶级域(如 `.com`, `.org`, `.net`)的权威 DNS 服务器
Step2
1 | nslookup -qt=NS com. d.root-servers.net |
在上面的服务器列表中选一个 向他询问com.的服务器
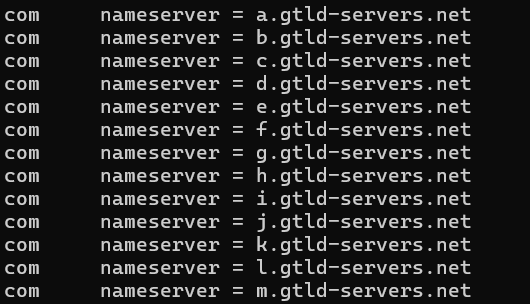
结果中的这些服务器中存着xxx.com.的 DNS 记录
Step3
1 | nslookup -qt=NS baidu.com. a.gtld-servers.net |
再向其中一个服务器询问下一级域名的 NS 记录
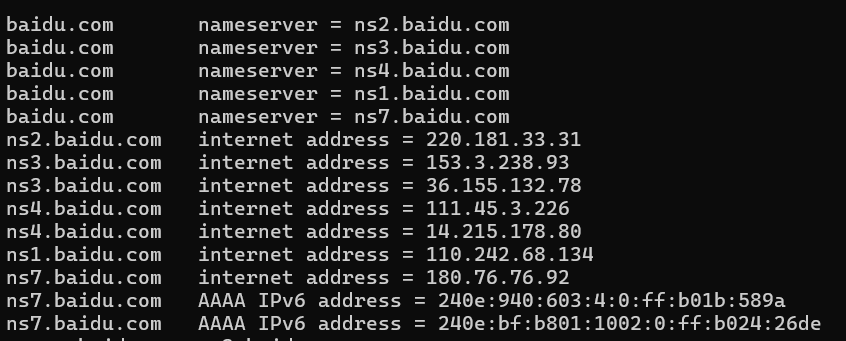
又得到了这一级的名称服务器地址与 IP 地址
Step4
如此递归查找,就能找到最准确的 IP 地址
整个流程分别查询了:
- 根域名服务器:根域名服务器提供顶级域名(TLD,如 .com, .org)服务器的地址。
- 顶级域名服务器:顶级域名服务器提供负责该域名的权威域名服务器的地址。
- 权威域名服务器:最终,权威域名服务器回答具体的 DNS 查询,返回域名对应的 IP 地址或其他记录。
注意:在有缓存的情况下可能不会这样递归查找,而是直接返回一个缓存中的 IP 地址(非权威应答),以提升效率。而在无缓存的情况下只能通过这样递归找到最准确的 IP
例 2:cubicy.icu
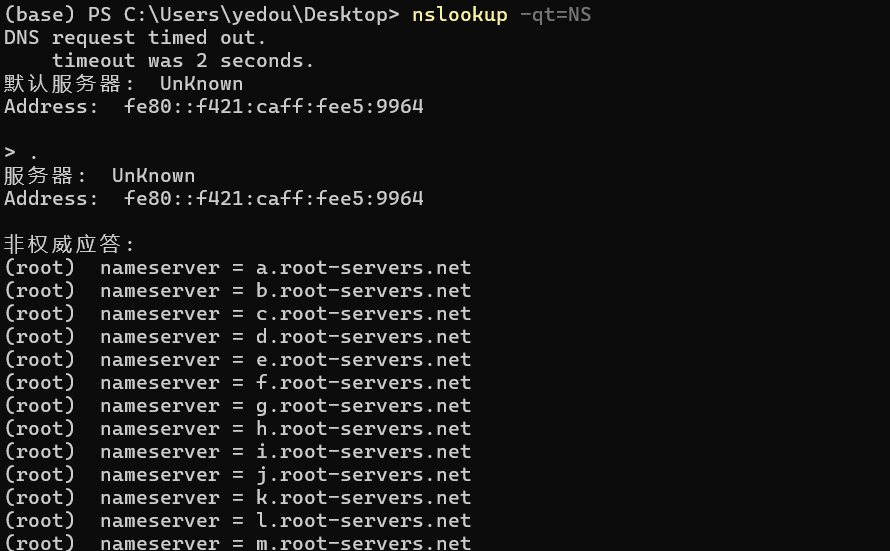
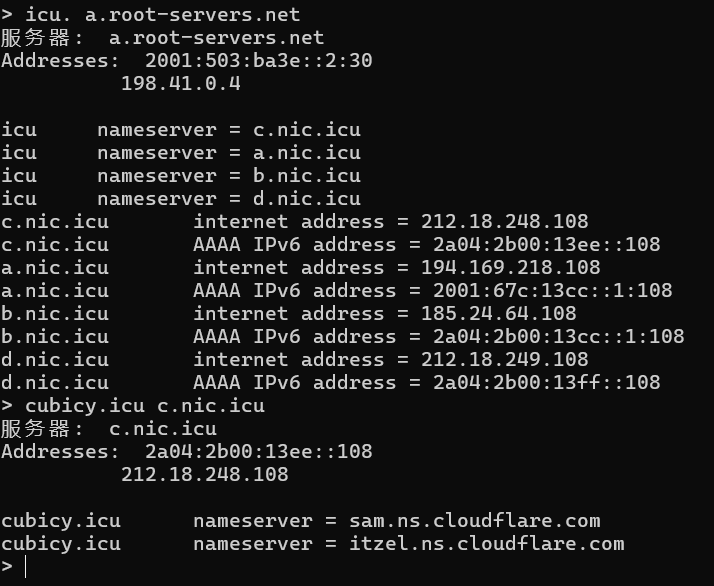 最终发现`sam.ns.cloudflare.com` 和 `itzel.ns.cloudflare.com` 是 `cubicy.icu` 的权威域名服务器(authoritative nameservers)。也就是说这两个 cloudflare 服务器最终将这个域名翻译成 IP 地址(IPv4:`212.18.248.108` IPv6:`2a04:2b00:13ee::108`)
最终发现`sam.ns.cloudflare.com` 和 `itzel.ns.cloudflare.com` 是 `cubicy.icu` 的权威域名服务器(authoritative nameservers)。也就是说这两个 cloudflare 服务器最终将这个域名翻译成 IP 地址(IPv4:`212.18.248.108` IPv6:`2a04:2b00:13ee::108`)
多次查询,却返回不同的 IP 地址
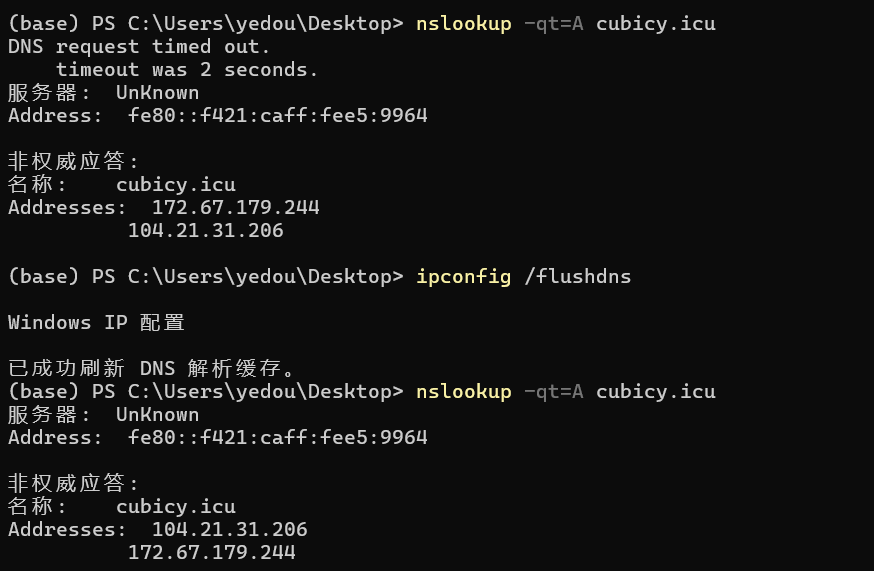
1 | ipconfig /flushdns |
在刷新 DNS 缓存以后重新查询相同域名的 IPv4 地址,发现返回的结果可能会不一样。也就是说,虽然用户都输入了相同的域名来访问网站,但是 DNS 却解析出了不同的 IP 地址,这样有助于分散用户的流量,减少服务器的负荷
DNS 作为电话簿 记录了什么东西
- A 记录(Address Record):将域名解析为 IPv4 地址。
- AAAA 记录(IPv6 Address Record):将域名解析为 IPv6 地址。
- CNAME 记录(Canonical Name Record):将一个域名指向另一个域名,实现域名的别名。
- MX 记录(Mail Exchange Record):指定邮件服务器的地址,用于电子邮件传递。
- TXT 记录(Text Record):用于存储任意文本信息,常用于验证域名所有权或存储其他信息。
- NS 记录(Name Server Record):指定域名服务器的地址,用于指示哪些服务器负责解析该域名。
- SOA 记录(Start of Authority Record):包含有关区域的权威信息,如主机名、电子邮件地址等。
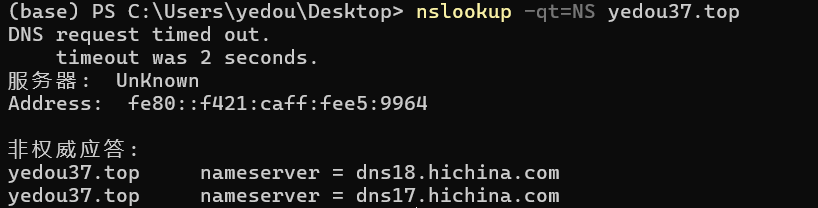
以 yedou37.top 为例
 可以看出解析记录中设置了
可以看出解析记录中设置了
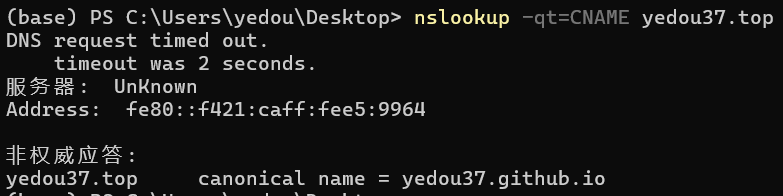
1 | CNAME : yedou37.github.io |
将yedou37.top和blog.yedou37.top都指向了另一个域名yedou37.github.io相当于这些域名都是该域名的别名
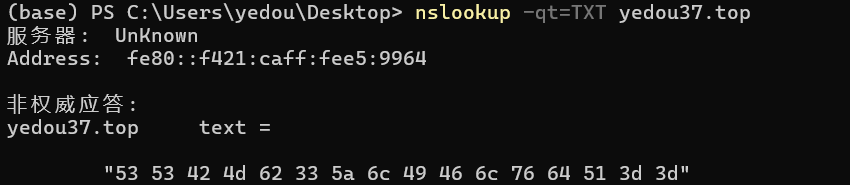
1 | TXT : .......... |
可以储存任何文本信息整活
也可以用来进行一些验证
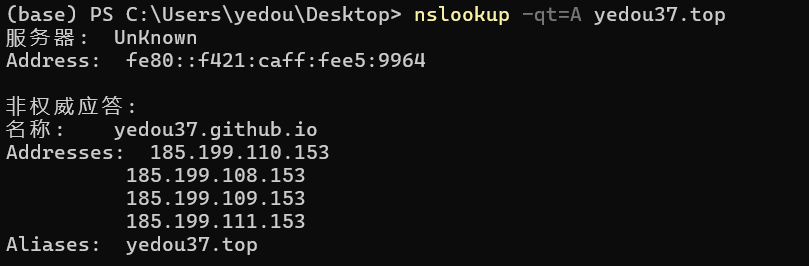
1 | A : 185.199.109.153 !!已经废弃 |
直接把这个域名解析成 IPv4 地址,进行访问
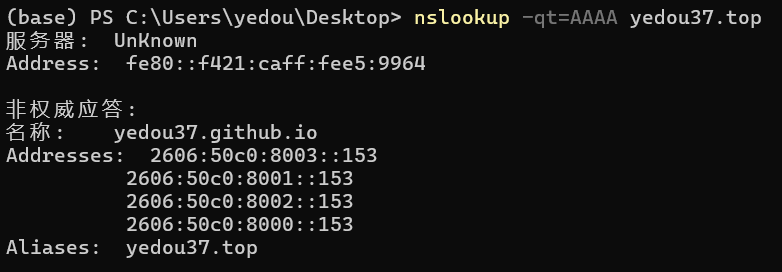
1 | AAAA: ____:____:____:____ |
同理,直接把这个域名解析成 IPv6 地址,进行访问
1 | NS : 域名服务器 |
指定域名服务器的地址,用于指示哪些服务器负责解析该域名
实际查询方法
1 | nslookup -qt=<要查询的DNS记录类型> <要查询的域名> |
例如:
HTTP :以学在浙大的登录过程为例
step1 请求
GET 请求这个网站的资源
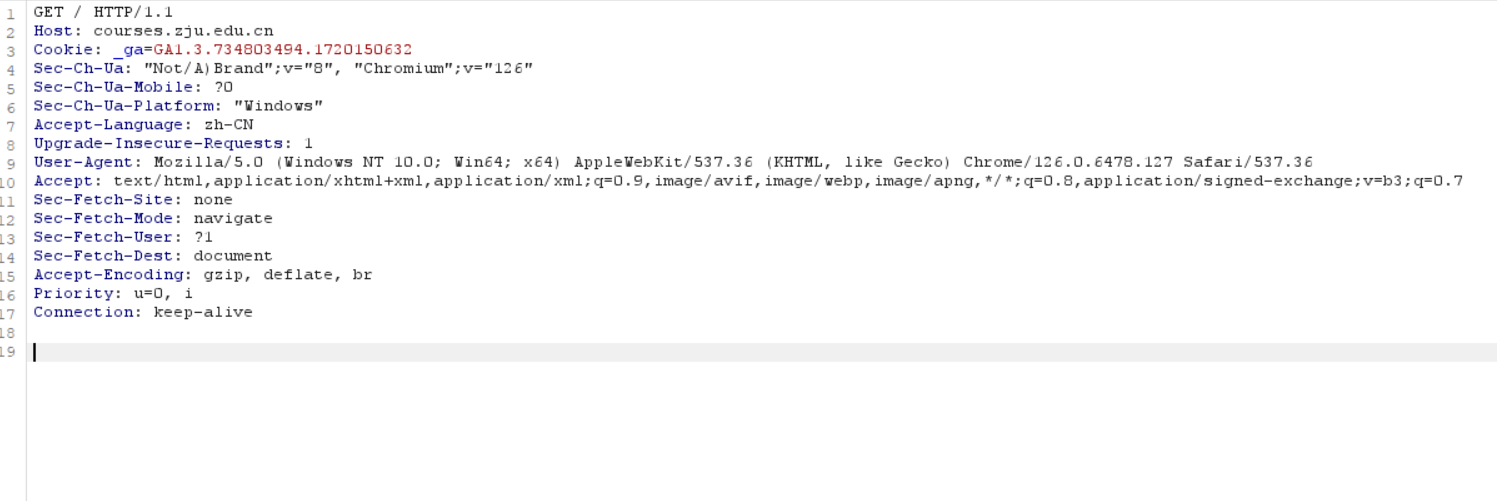
本条是客户端向服务端发送的第一条请求报文
1 | GET / |
请求行
请求方法:GET 指的是获取资源
协议版本:HTTP/1.1
URL:courses.zju.edu.cn/ 即为学在浙大域名(其实是/资源相对路径 + Host 主机信息)
请求首部:(GPT)
Host: courses.zju.edu.cn: 指定了请求的目标主机。Cookie: _ga=GA1.3.734803494.1720150632: 包含了客户端的 Cookie 信息,用于跟踪用户状态。Sec-Ch-Ua: "Not/A)Brand";v="8", "Chromium";v="126": 指定了浏览器和平台的信息。Sec-Ch-Ua-Mobile: ?0: 指示请求是否来自移动设备。Sec-Ch-Ua-Platform: "Windows": 指定了请求的平台。Accept-Language: zh-CN: 指定了客户端接受的语言。Upgrade-Insecure-Requests: 1: 指示客户端愿意接受不安全的 HTTP 请求。User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.127 Safari/537.36: 包含了客户端的用户代理信息,用于标识客户端的浏览器和操作系统等信息。Accept: 指定了客户端可以接受的响应内容类型及优先级。Sec-Fetch-Site,Sec-Fetch-Mode,Sec-Fetch-User,Sec-Fetch-Dest: 这些头部信息用于指示请求的来源、模式、用户状态和目标。Accept-Encoding: 指定了客户端可以接受的内容编码方式。Priority: 指定了请求的优先级。Connection: keep-alive: 指定了连接保持活动状态,以便在同一连接上发送多个请求。
请求体:这里没有。因为请求行和请求首部已经包括了足够的信息
Step2 响应
OK 但是你先重定向到登录界面再说
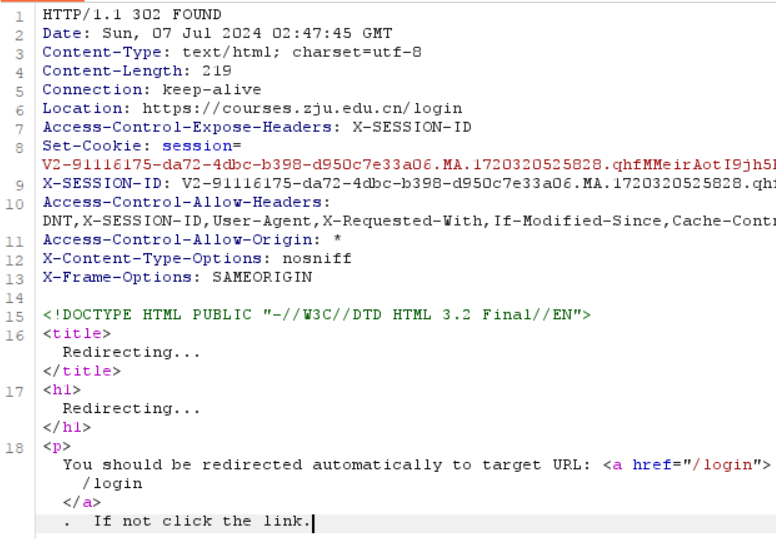
响应行:
HTTP/1.1 302 FOUND: 这是响应行
HTTP 协议版本: HTTP/1.1
状态码: 302 FOUND 表示临时重定向
响应首部
Date: Sun, 07 Jul 2024 02:47:45 GMT: 指示了响应生成的日期和时间。Content-Type: text/html; charset=utf-8: 指示了响应体的内容类型和字符集。Content-Length: 219: 指示了响应体的长度。Location: https://courses.zju.edu.cn/login: 指示了重定向的目标 URL。Set-Cookie: session=V2-91116175-d......: 设置了一个 Cookie,用于在客户端保持会话状态。X-SESSION-ID: V2-91116175-d....: 提供了一个Session ID 这部分存储在服务器中
响应体
是一个HTML文件,用于展示重定向临时界面
Step3
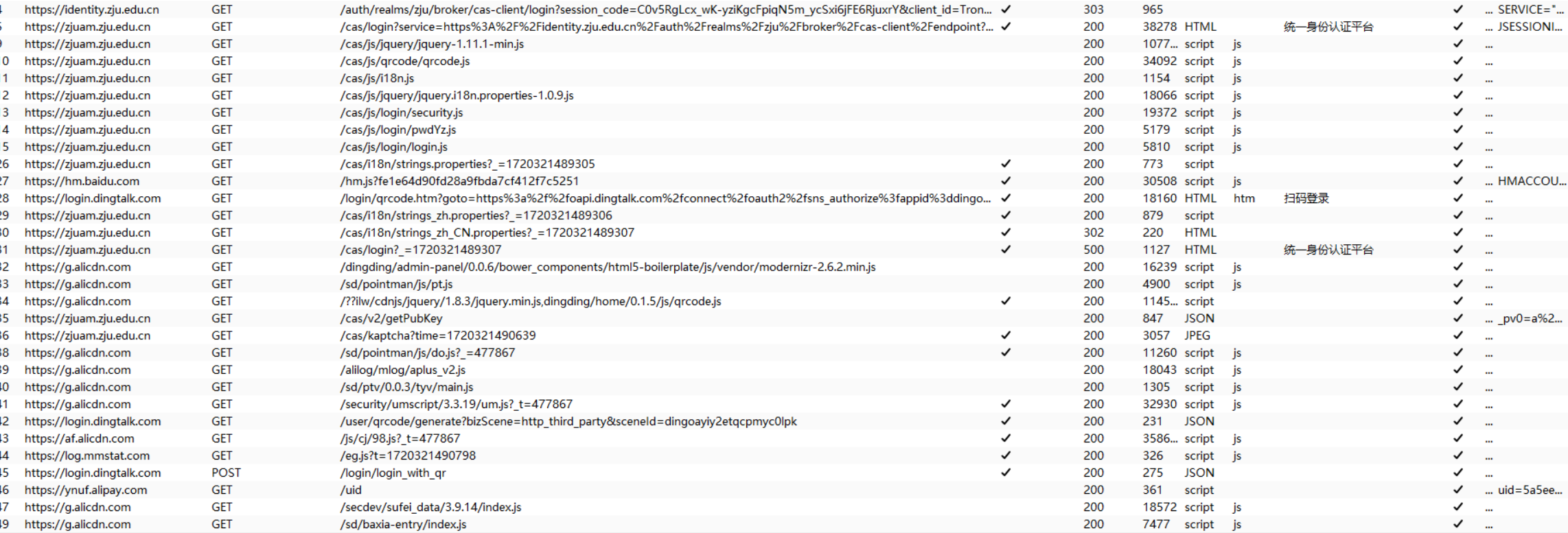 通过一连串的`GET`请求报文向阿里巴巴 CDN 请求资源以及向钉钉请求二维码登录的资源。经过层层跳转,最终成功到达统一身份认证平台
通过一连串的`GET`请求报文向阿里巴巴 CDN 请求资源以及向钉钉请求二维码登录的资源。经过层层跳转,最终成功到达统一身份认证平台
Step4
用户名是密码是发送
请求报文:
1 | POST /cas/login?service=https%3A%2F%2Fidentity.zju.edu.cn%2Faut...... |
请求行
请求方法:POST 用于传输实体主体:在这里是我登录用的账号和密码
请求头部
。。。
请求体
在这里包括我的学号和密码+一些操作和信息
Step5
认证成功,以后用这个东西认证就好了,不用再输入账号密码
响应报文 1 转到identity.zju.edu.cn 同时给你一个state一个ticket证明你的身份
1 | 302 |
请求报文 2 + 响应报文 2
向identity.zju.edu.cn发送一堆 cookie 证明可以登录了
1 | GET /auth/realms/zju/broker/cas-client/endpoint?state=5A9GipBkotbjm..............FBm3bXWT7Ghfh9UMU.glQy8ZGwcWc.TronClass&ticket=ST-532998-xnrcb5Z.......Y6-zju.edu.cn |
回应:好的,再设置一堆 cookie 并重定向一下
1 | 302 Found |
请求报文 3 + 响应报文 3
这里的请求报文 cookie 中出现了 session ID 作为会话的唯一标识,从此刻开始,客户端与服务端进行通讯就是在相互交换这个 session ID 来证明彼此的身份了,只要这个 session 仍然在这样维持着,就维持了这个客户端的登录状态,不需要重复输入用户名和密码来证明身份了
1 | session=V2-22215...a8-f474-43a2-ae3f-14f3ef36d78a.MA.1720....40602.7r_GernKC8laNTavpx9W6cjiqgU |
1 | GET /user/index?ticket=ST-d30043c2-0c13-4f49-a27d-6c127cbfb709.ea3335eb-9469-4e80-9201-14dec28fed32.818132fc-7f3a-49de-b1dd-3fe43bff7371 |
回应: 再重定向(302 FOUND)一下,并且设置一个新的 session ID
1 | Set-Cookie: session=V2-1-c6b8...2-6af1-4214-b6a9-ad9bdd5653cf.MjQzNDU2.172....2963.PZl62CoVc4i0gaY6mGl-gDJibjU; |
1 | 302 FOUND |
Step6
到达指定的界面 开始请求资源:通过 session ID 作为标识,维持登陆状态
请求报文 1+响应报文 1
请求course.zju.edu.cn/user/index即学在浙大用户首页的资源
注意到:这时的 session ID 正好就是上一条响应报文所设置的 session ID(....-gDjbjU) 说明此时客户端与服务端之间已经再用 session ID 作为相互认证的凭证了
1 | GET /user/index |
回应:状态码终于不是302重定向 而是200 OK成功处理请求。同时,又下达了设置新的 session ID 的命令:
1 | Set-Cookie: session=V2-1-c.....55G9Alo730aNlO4t2lc; |
可以预见,下一个客户端的请求报文就会使用这个新的 session ID 作为 cookie 的一部分,以证明自己的身份并维持这个会话
在响应体中,服务器也发送了主页面的 HTML 文件用于显示这个网页
1 | 200 OK |
Step7
请求更多资源并维持会话
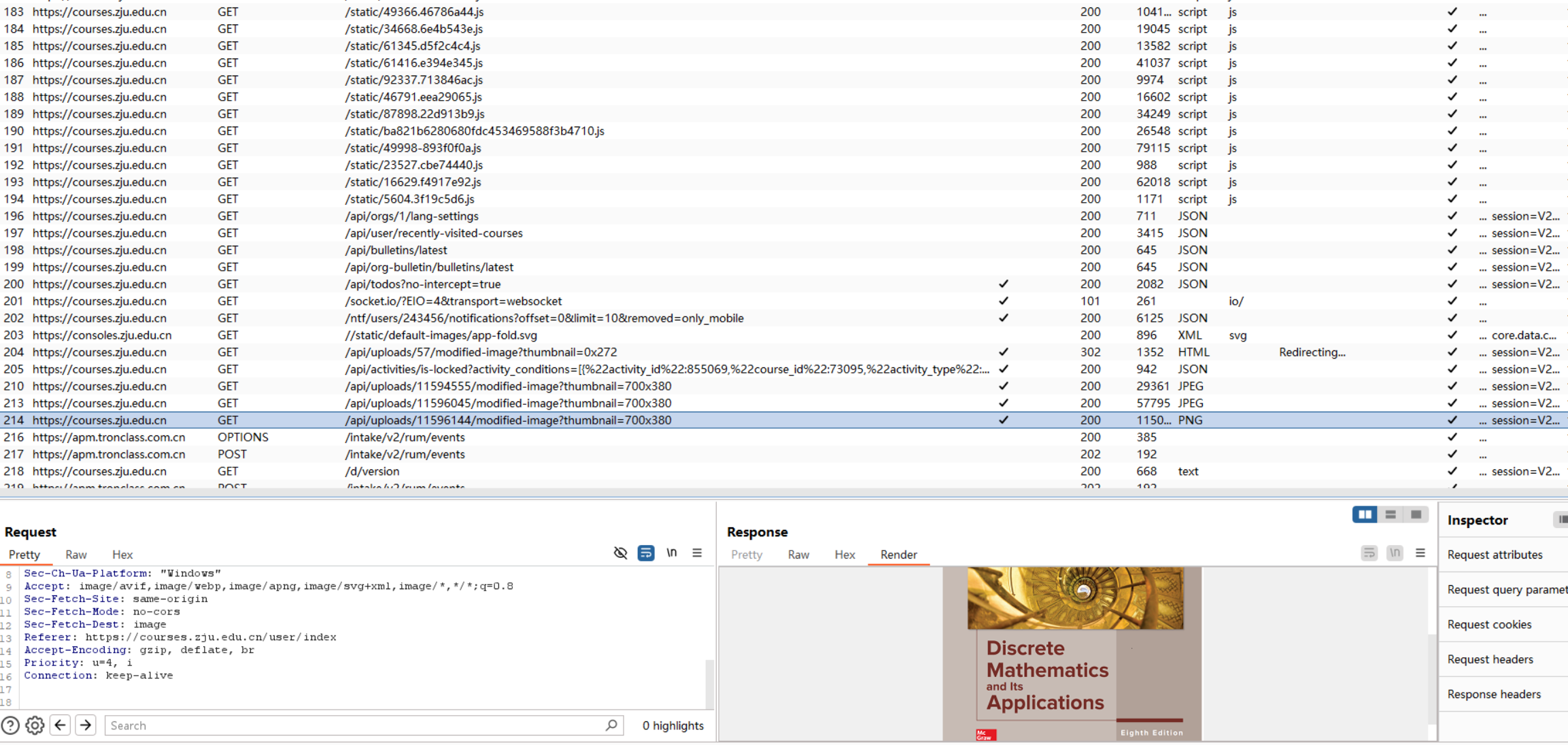
可以看到:客户端接着向服务器请求了更多资源(GET),但是似乎只有一些重要或是涉及隐私的资源被请求以后,服务端才会要求设置新的 session ID Set-Cookie: session=...比如“最近访问的课程”、“课程图片”等,例如上图的 214 条 GET 请求就返回了离散数学课程的封面图并且马上要求更换了 session ID。其他一些 js 脚本的请求都暂时使用同一个 ID。
最终成功进入并加载完成了主页面
请求和响应报文
请求报文结构:
- 第一行是包含了请求方法、URL、协议版本;
- 接下来的多行都是请求首部 Header,每个首部都有一个首部名称,以及对应的值。
- 一个空行用来分隔首部和内容主体 Body
- 最后是请求的内容主体(可以没有这部分)
1 | GET http://www.example.com/ |
响应报文结构:
- 第一行包含协议版本、状态码以及描述,最常见的是 200 OK 表示请求成功了
- 接下来多行也是首部内容
- 一个空行分隔首部和内容主体
- 最后是响应的内容主体
1 | 200 OK |
HTTP 方法
请求报文->请求行->方法字段中规定的方法
- GET:从服务器获取资源。GET 请求通常用于请求服务器发送某个资源,而不会对服务器上的资源产生任何影响。
- POST:向服务器提交数据。POST 请求通常用于向服务器发送数据,比如提交表单或上传文件。
- PUT:在服务器上创建或更新资源。PUT 请求通常用于将数据存储到服务器上的指定位置。
- DELETE:从服务器删除资源。DELETE 请求用于请求服务器删除指定的资源。
- PATCH:对资源进行部分修改。PATCH 请求用于对资源进行局部更新。
- HEAD:类似于 GET 请求,但服务器只返回头部信息,不返回实际内容。HEAD 请求通常用于获取资源的元数据,比如大小或类型,而不需要获取实际内容。
- OPTIONS:获取目标资源支持的通信选项。OPTIONS 请求用于获取服务器支持的 HTTP 方法列表,或者查看服务器支持的特定资源的通信选项。
- TRACE:回显服务器收到的请求,用于测试或诊断。TRACE 请求通常用于测试或诊断,客户端可以查看服务器收到的原始请求内容。
其中,DELETE PUT 方法不带有身份验证,比较危险。TRACE 方法同样容易遭受攻击



![[课程笔记]2024春夏 ZJU 数据结构基础](https://s2.loli.net/2024/07/15/tZBwHEjfqLKs45x.png)
![[misc]网站搭建中使用的python脚本和HTML前端代码](https://s2.loli.net/2024/07/15/eM2UuLr5t37XmF9.png)
![[CS学习]计算机网络](https://s2.loli.net/2024/07/15/3gzkTo129CQZXKP.png)
![[CTF技术]SQL注入攻击](https://s2.loli.net/2024/07/14/AJYsj9Mu2VKmHnz.png)